As a FYI, I have taught Artificial Intelligence for Chapman University, worked as a AI/Software developer for Amazon and Microsoft. Artificial Intelligence is composed of a large number of very different techniques, at one end you have “ponies” and at the other end “Space Shuttles”. One technique, expert system with fuzzy logic (ESFL), appears to be the best. Why? Most of the techniques require vast quantity of training data and usually produce black box suggestions/predictions which lacks explanations of why. ESFL provides a complete logic/evidence trail for each suggestions/predictions which can be walked. If one piece of evidence is disputed, it can be removed easily and a new set of suggestions/predictions produced.
Build our own AI Autism Model?
This post comes from the success of using AI on Microbiome Prescription. It would be nice to see if we can do the same with Autism. The goal is to use all available knowledge from studies.
I would suggest using SWI-PROLOG as the main engine. Prolog is a language that does not compute numbers but compute logic. The following is actual program code. It is almost english-like and prolog can resolved what you should take or not take.
- increases(Modifier_A,Bacteria_31979).
- decreases(Modifier_X,Bacteria_1236).
- low(“person”,Bacteria_1239).
- high(“person”,Bacteria_1234).
- helps(Person,Modifier) :- high(Person,Taxon),decreases(Modifier,Taxon).
- helps(Person,Modifier) :- low(Person,Taxon),increases(Modifier,Taxon).
- hurts(Person,Modifier) :- low(Person,Taxon),decreases(Modifier,Taxon).
- hurts(Person,Modifier) :- high(Person,Taxon),increases(Modifier,Taxon).
- take(Person,Modifiler) :- remove(helps(Person,Modifier),is,hurts(Person,Modifier)).
- contradict(Modifier,Taxon) :- decreases(Modifier,Taxon),increases(Modifier,Taxon).
“take” above says get the list of items that helps and then removes all items that hurts. I.e. only items without contradictions.
The number of lines (statements) to explicitly write Microbiome Prescription in SWI-PROLOG is about 15 million statements. That code code be licensed (for free or nominal cost) to a project of this type so building such a microbiome resource is not needed; rather just augment that data with autism specific data.
One key difference between ESFL is the ability to infer and not just parrot (typical Machine Learning). Bacteria A increases IL 10. A person with SNP ABC has decreased IL 10, thus we can desired to increase Bacteria A for people with SNP ABC.
Vision – Do it For Autism!
I have a web based data entry system (that is being used commercially) that can be made available to the project (with hosting of site and database). We have an almost ready to run system.
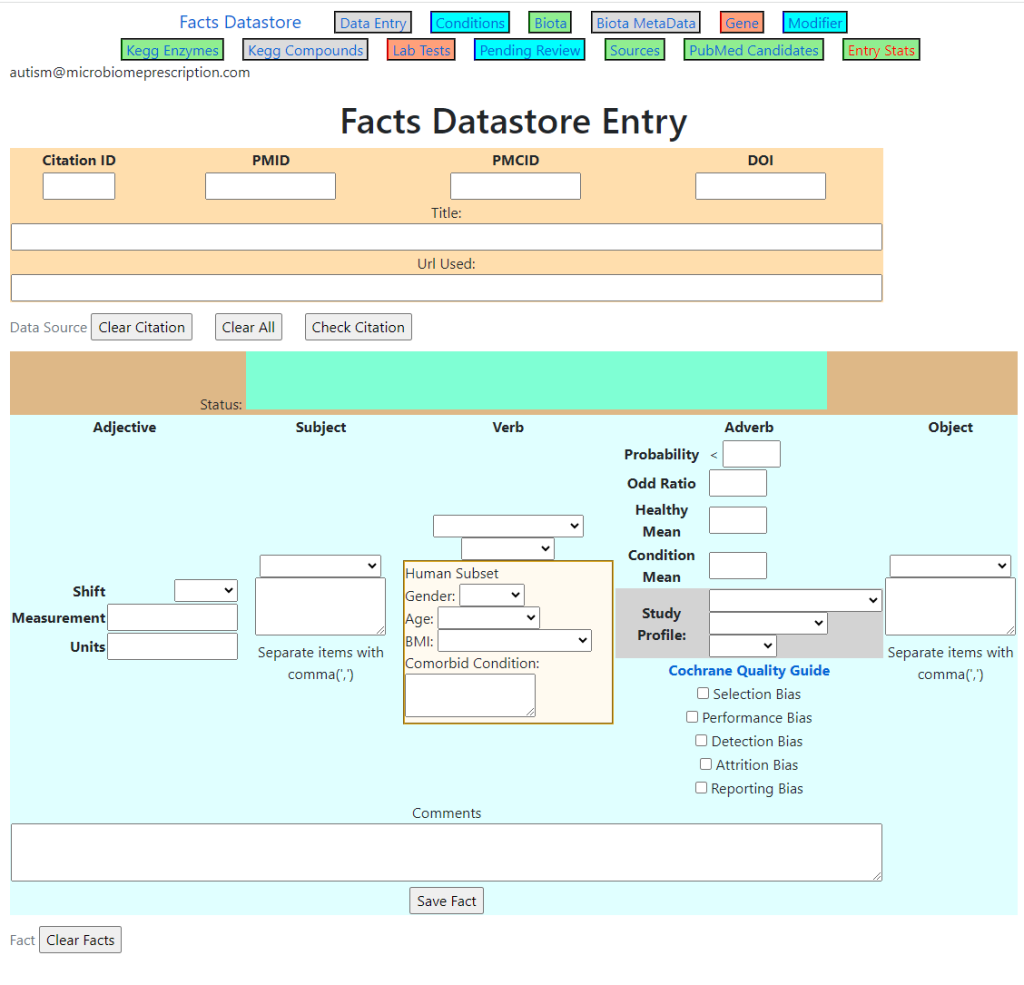
The Rub
This is a time consuming process to enter the data and then have the data reviewed (to insure correctness). Typically the people doing the entry and reviews are M.Sc., Ph.D. or M.D. Using students working on their degrees (summer work, part time) to do entry is often a way of keeping costs down. These students typically have access to the full text of articles through their educational institutes.
- Typical time per study/article is 30 minutes to read and enter, 10 minutes to review
- There are 72,000 studies citing Autism on the US National Library of Medicine.
- A complete coverage would be 36,000 hours or 900 man-weeks or a team of 18 people working full time for a year.
- The expected number of facts will likely be around 120,000.
Facts should be put in a Public Domain Type of License
This allows other groups to continue the work and prevents the need to duplicate the effort of encoding the same studies multiple times. The terms of license should require people that uses and extends it to also make their additional data available under the same terms.
Benefits
One of the key benefit is the identification of gaps in the knowledge base as well as identifying areas where there are contrary results. This allows better funding of research to fill gaps and not duplicate existing work.
A secondary benefit is that it could always be kept current and provide far more specific data for a patient based on all of the information available. The issue of MD’s knowledge being stale or bias is reduced.
What is needed — FUNDING AND MANAGEMENT
The Rub above takes money to happen — even if you are paying students the minimum wage, we quickly get a significant cost. Ideally one or more existing Autism Organizations can be persuaded to partially or fully fund this project.
My own role would be at most, a process consultant. Working Pro Bono.
Maybe this could be a nice match for a large-language model (LLM)? In its initial demo video, Google’s Gemini was used to parse a lot of pubmed abstracts for genetic data. This particular task is more complicated but I suspect using something like a “tree of thoughts” approach with a LLM might help (it likely won’t be as good as a human but perhaps still useful).
I have tried several and the accuracy of correct reading is too low. For medical issues, “good enough” is rarely good enough